
De laatste tijd zien we weer veel meldingen van zorgfraude. Eén van de manieren waarop fraude in deze sector zich uit heeft betrekking op de facturatie van uren. We moeten daarbij wel een onderscheid maken tussen fraude en onregelmatigheden. In het ene geval is er sprake van moedwillig kwade opzet; in het andere geval zijn dat zaken die voortkomen uit fouten of administratieve onmogelijkheden. Maar soms is die lijn bijzonder dun.



Door: Patrick van Emden en Thomas Helling
Follow the Money heeft met haar onderzoek van de jaarrapportages van zorgorganisatie laten zien dat er soms veel verschillen zijn in (operationele) winsten van zorgorganisaties. (1) Bij het onderzoek werden winstpercentages hoger dan 10 procent als opvallend gemarkeerd. Vervolgens werden de opvallende zorginstanties verder onderzocht door te kijken naar bijvoorbeeld de opbrengst per fte of zaken als de kosten per klant. Zorginstanties aan de care-kant zijn gelimiteerd aan het maximaal aantal uren dat gemaakt kan worden door de zorgverleners. Daarom is de opbrengst per fte aan grenzen gebonden. Indien deze verhoudingen extreem hoog liggen kan er sprake zijn van fraude, of heeft de organisatie een bijzonder efficiënte bedrijfsvoering.
Het is naast de cijfers op jaarniveau ook interessant om te kijken naar de verschillen tussen wat een gemeente aan uren geïndiceerd heeft en wat er in de praktijk gefactureerd wordt. In sommige gemeenten wordt geëxperimenteerd met systemen die daadwerkelijke uren registeren in samenwerking met bepaalde zorgaanbieders. Dit gaat bijvoorbeeld via (blockchain)-oplossingen met administratievriendelijke NFC-chips en apps die uren (en anderszins) bij cliënten registreren.
Transparantievoorvechter FairCare maakt onderscheid tussen diverse typen uren: door de gemeente geïndiceerde uren, door de zorgorganisatie ingeplande uren, gefactureerde uren en daadwerkelijk bij de cliënten gerealiseerde uren. In de meeste administraties vormt de planning de basis voor de facturatie. Het aantal gefactureerde uren komt dan grotendeels overeen met de geplande uren.
Dat kan komen doordat het administratief-technisch lastig is om bijvoorbeeld no shows, ziekmeldingen van medewerkers en cliënten, maar ook extra bestede tijd goed en tijdig te verwerken in een urenadministratie. Het aantal daadwerkelijk gerealiseerde uren kan en zal natuurlijk afwijken van het aantal geplande uren.
Veel gemeenten zien dat de daadwerkelijk gefactureerde uren (bij P*Q financiering) grofweg 30 procent lager liggen dan de door de gemeente geïndiceerde uren. Er wordt dus bijna 1/3 minder zorg gepland dan er aan uren geïndiceerd zijn.
Hier liggen een aantal interessante zaken om te onderzoeken. Blijkbaar laten zorgaanbieders productiemogelijkheden liggen. Is dat vanwege het niet kunnen invullen of weet men vanuit de praktijk al dat er minder nodig is dan de theoretische inschatting van de gemeentelijke consulenten? De duiding van deze cijfers kunnen per gemeente en zorgorganisaties verschillen, maar dat er optimalisatiemogelijkheden zijn is duidelijk. Een bron vanuit een zorgverzekeraar gaf in reactie hierop aan dat men in 2006 al vaak met zorgaanbieders overeenkwamen om maar 75 procent van de indicaties te vergoeden. Daarnaast bieden de verschillen tussen geplande uren en daadwerkelijk gerealiseerde uren mogelijkheden voor zorgaanbieders en gemeenten om in overleg bijvoorbeeld de verschillen te delen, waardoor zorgaanbieders minder administratie hebben en gemeenten lagere kosten. In ieder geval genoeg zaken om te overdenken vanuit deze verschillende perspectieven.
De verregaande technieken op het gebied van Data Science bieden steeds meer inzicht in het sociaal domein. We kunnen met uitgebreide analyses inmiddels snel afwijkingen vinden die nader onderzocht dienen te worden. Simpele methoden, zoals het herkennen van (bijna) dubbele declaraties, verschaffen snel inzicht in foutief betaalde declaraties of facturen. Door data visueel te presenteren vallen merkwaardigheden sneller op. Met behulp van Data Mining kunnen we patronen herkennen en afwijkingen vinden ten opzichte van hetgeen er verwacht wordt in de data.
Het voordeel van deze technieken is dat zij in staat zijn verdachte data punten te vinden die mensen eenvoudig over het hoofd zien: het is echt datagedreven. In de financiële wereld worden bijvoorbeeld frauduleuze transacties vroegtijdig herkent met behulp van Machine Learning-algoritmen. Door een combinatie van locatie, tijd, bedrag, apparaat, en diverse andere dimensies te vergelijken met transacties uit het verleden, kan bepaald worden of iets een valide transactie betreft.
Een soortgelijke aanpak zou kunnen werken voor declaraties. Door declaratiegedrag van verschillende aanbieders samen te vatten in een aantal dimensies en naast elkaar te leggen, kan bepaald worden wat voor declaratiepatronen afwijken van de norm. Er bestaan diverse technieken die hier in kunnen voorzien, zoals de techniek ‘What’s strange about recent events?’. Die helpen in het detecteren van significant verdachte groepen van datapunten.
Een andere bekende datagedreven methode om fraude te detecteren is het toepassen van de wet van Benford. Is het je wel eens opgevallen dat een getal vaker begint met een 1 dan met een 9? Dit begincijfer betreft het voorste cijfer in het volledige getal, bijvoorbeeld 5 in 57, of 3 in 0.00324. De wet van Benford zegt dat de frequentie van de begincijfers aflopen, zoals hieronder weergegeven is (bron):
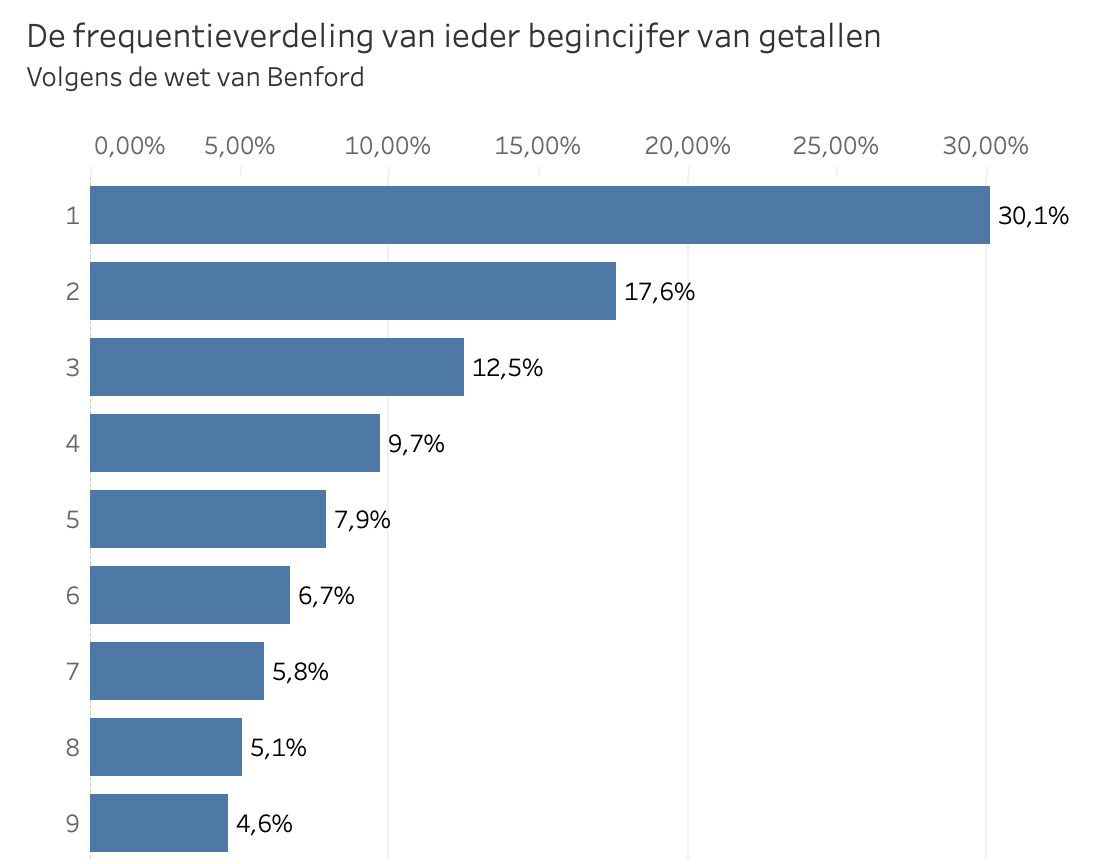
In 1972 bedacht de econoom Hal Varian dat de wet van Benford gebruikt kan worden om mogelijke fraude op te sporen in lijsten met socio-economische gegevens ter ondersteuning van overheidsbeslissingen. Hij baseerde zich op de veronderstelling dat mensen die zelf getallen uitvinden geneigd zijn de cijfers uniform te verdelen. Door de frequentieverdeling van de eerste en volgende cijfers van de getallen te vergelijken met de verwachte verdelingen volgens de wet van Benford, kunnen opvallende patronen, of kunstmatig ingevulde cijfers, snel en geautomatiseerd opgemerkt kunnen worden. Verdergaand op dit idee toonde de econoom Mark Nigrini aan dat afwijkingen van de wet van Benford ook gebruikt kunnen worden als indicator van vervalsing van een boekhouding of uitgavenfraude. (2)
Het zou interessant kunnen zijn om de facturatiegegevens van bepaalde zorgaanbieders langs de wet van Benford te leggen om afwijkingen te meten en fraude op een datagedreven manier bloot te leggen.
Er lijken verschillende manieren te zijn om met fraude om te gaan. Eén van de manieren is om in te zetten op maximale transparantie. Hierin zijn de opdrachtnemers transparant in hoeveel uren er gemaakt worden en de doelmatigheid daarvan. Dit in ruil voor een fair tarief waarin ook zaken verwerkt zitten als overhead, no show, ziekte van cliënten (en medewerkers), maar ook met ruimte voor innovatie. Een andere insteek is om onder andere met behulp van Data Science in te zoomen op afwijkingen, die te onderzoeken en mogelijke fraude bloot te leggen en aan te pakken. Het zou daarnaast interessant kunnen zijn om beide manieren toe te passen. Bijvoorbeeld door Data Science toe te passen op grote landelijke of regionale bestanden, al dan niet met ondersteuning vanuit VNG of VWS, en lokale regio’s en gemeenten in te laten zetten op transparantie middels hun contracten.
Bron: https://www.ftm.nl/artikelen/jeugdzorg-waar-bleven-de-miljarden?&utm_source=nieuwsbrief&utm_medium=email&utm_campaign=DataJeugdzorg
Bron: https://nl.wikipedia.org/wiki/Wet_van_Benford









